 Tech Notebook by Lucas
Tech Notebook by Lucas
AWS re:Invent 2019: Data-Driven, Cloud-Native Ecosystem
Note Repository
Characteristics of Automotive Ecosystem
- Connectivity: on-demand services
- Autonomous Driving: push towards full autonomy. Lots of sensors, camera readers, up to 25TB/day of data
- Multimodal Mobility: point A to point B
- Marketplace: whole list of contextual, local, location-based services like food ordering & payment, hotel reservation, offer from dealership
- Electrification: very pervasive on ride-sharing and micro mobility (scooters, bikes) solutions
- Subscriptions: car makers are becoming software and service companies (eg: make cars for subscription)
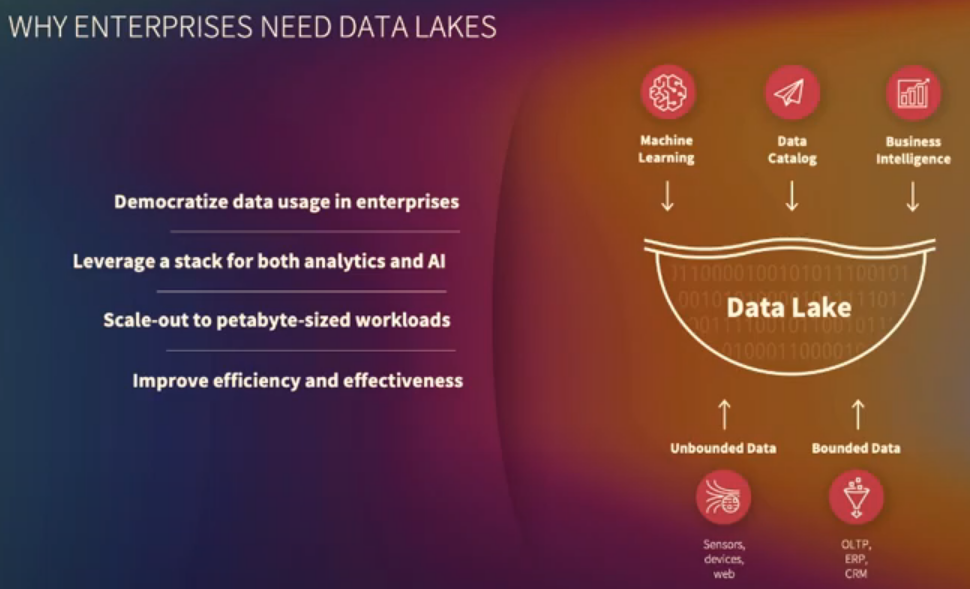
Three main features of Data Lakes
- Single point of truth: work on same data without moving it around, from R&D to manufacturing to logistics to after-sales. Democratizing the data usage in the enterprise.
- Support various data formats: from rational to non-rational data. Car sensor data, images from autonomous driving, etc.
- Scales storage and compute individually.
Intro to BMW’s Solution
- BMW Intelligent Personal Assistant (IBM Assistant) - “Soul of your BMW” - focused on becoming more connected and more contextualized
- Has to be properly integrated with Manufacturing, Logistics, Customer Service, After-Sales
- They want to transform BMW into a truly data-driven company
- Driven by:
- Data & AI
- Cloud stack: pooling and providing the right tools and frameworks to work with data in most effective ways - leverage good, complete cloud stack - move away from heterogeneous landscape
- Emerging tech: novel/unproven tech (eg: natural language processing, blockchain, etc) shouldn’t be avoided
Motivation
(Why BMW started aggressively pursuing cloud solutions in 2019)
- 2014: Big Data journey - Hadoop + Kafka stack (fueling data transformation on top of the Hadoop ecosystem). Ingested both IoT and Product (ERP, CRM, OLTP) data via Kafka or Spark.
- Eventually purpose-built databases started being introduced to speed up workloads (eg: PostgreSQL) trying to satisfy customer requirements
- Lastly, to harness the results of the data analysis, in 2016 a K8s cluster was introduced.

Very heterogeneous landscape. Consequences:
- Only fractions of critical organization’s data were able to be ingested.
- Bottlenecks were prominent. There were central teams taking care of data ingestion, no self-service. Scaling workforce didn’t help.
- Move to purpose-built sandboxes for experiments (eg: Docker, Jupiter Notebooks, traditional solutions, etc).
- The number of prototypes spinning out in different environments was growing exponentially bigger than products being made.
The whole (small) DevOps team had full and trained responsibilities over all the components. Those reasons led BMW to move to the cloud.
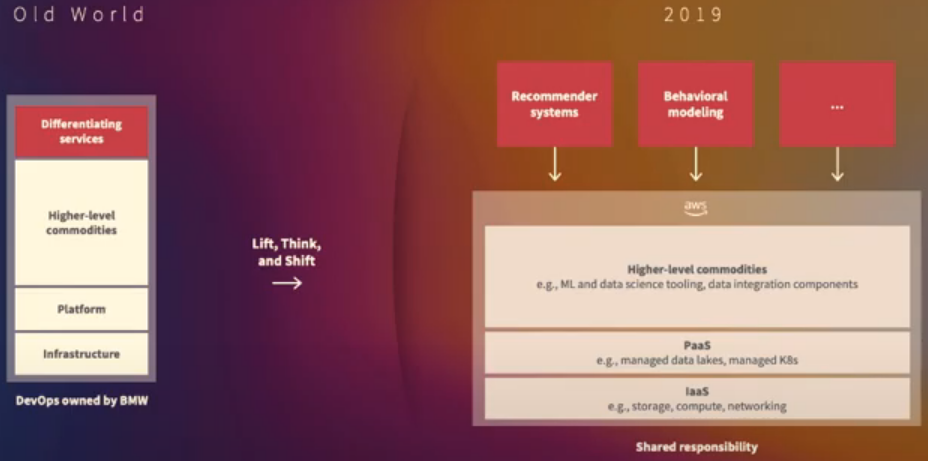
Lift, Think, & Shift: re-architecture of major parts of the on-premises platform into the cloud, not just duplicate the combobulated environment it currently had. Move of major parts into AWS primarily built upon cloud-native building blocks and IaaC
That shift allowed BMW to focus more on the differentiating “bits and pieces” (services) and the quality of their data rather than making sure the tools, platforms, and infrastructures worked and communicated properly
Hypothesis that supported the move to the cloud:
- BMW will not be able to keep up with the radical pace of innovation AWS has in their data lakes services portfolio
- making sure that BMW understands, curates, transforms, and leverages their data as opposed to wasting time with anything else
BMW Group’s Cloud Data Hub
(Platform design of the Cloud Data Hub built upon AWS)
Three main premises:
- Enable a very quick infrastructure setup in different regions while maintaining high security standards and complying with regulations
- Support quick data integration for a wide array of datasets (both streaming and relational)
- Provide consistent means of how people will interact with the data and how identities are managed across the platform (eg: SSO, making sure it translates well into the enterprise scenarios)
Three-layered approach:
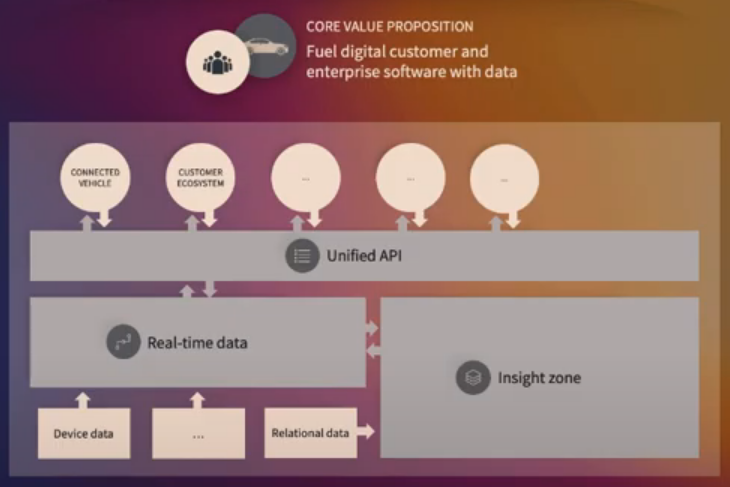
- Real-Time Zone: keeps cached copies of real-world objects (eg: customer vehicles) for fast access to non-historic sized data needed for inference of ML models
- Insight Zone: historicized versions of real-time objects and also plays well with already existing relational databases (OLTP, data warehouses, etc)
- Unified API: collection of restful API that makes interaction of people & systems w/ data easy, and gives the ability to expose both real-time and relational data very effectively
Three important things about data platform:

- Democratization: provide easy access to both bounded and unbounded data. Single point of truth for any kind of data analytics. Enable data stewards to intuitively look at what’s already there. Introducing a data catalog built in-house upon the existing Cloud Data Hub for exploration
- Modularity: key to enable broader community to work with the platform. Allows users to bring their own building blocks too
- Lean Ops: avoid putting all the effort and energy into the system, let AWS handle infrastructure. Fast-paced environment to drive innovation
Cloud Data Hub GUI
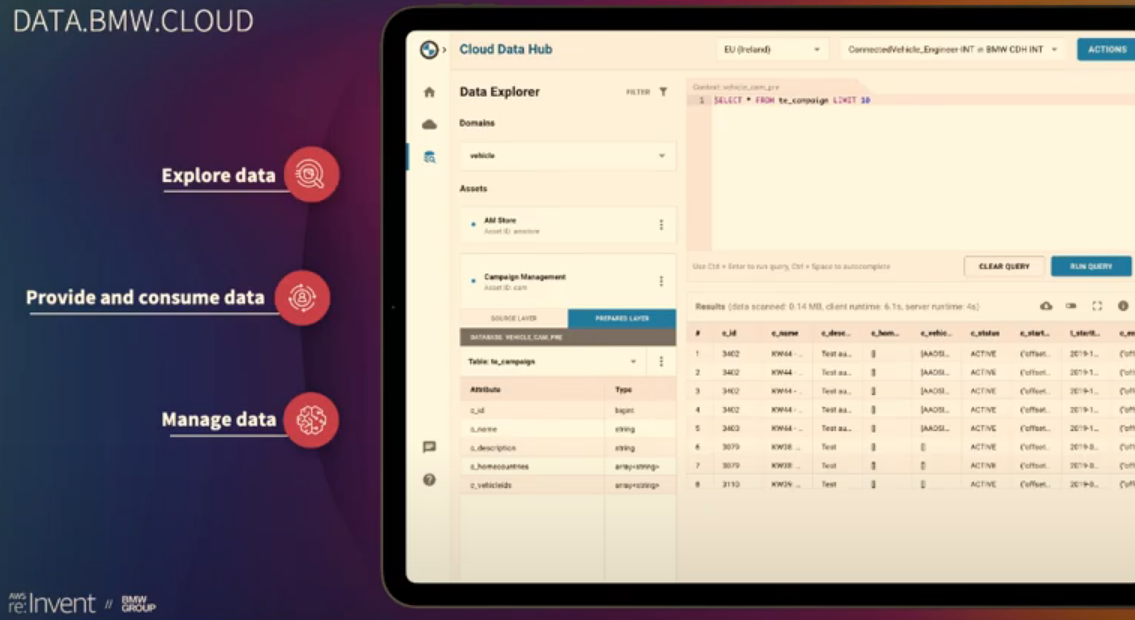
Client Flow:
- Login
- Select Role
- Launch CDH
- Make queries
Providing Data: very difficult, many ETL tools but always hits limitations and bottlenecks when implementing.
- Option 1: Terraform template
- Option 2: Manually via Hub (config & auth, ingest source, scheduling)
Older flow used EMR. Newer flow uses Lambda, CDK, CloudFormation orchestration.
Data Consumption
- Consumer requirements for data consumption: SPARK. Many data analytics points start with Spark.
- Cloud Data Hub gives customers the ability to spin up a customizable Sage Maker stack with an EMR cluster. You can also open a Jupyter Notebook that directly interacts with the EMR cluster.
Data Ingestion

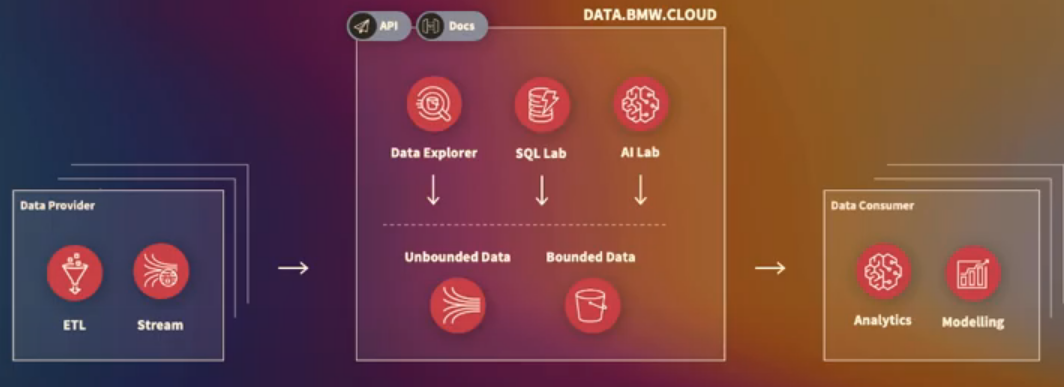
DATA.BMW.CLOUD: Store all bounded and unbounded data, build tools on top of that (eg: BMW CDH Portal) to give great and easy customer experience.
Data Provider: very easy and customizable to bring data into CDH:
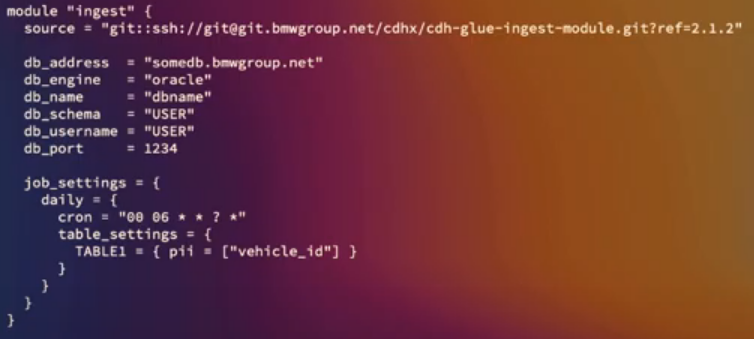
What’s provisioned by the Terraform module inside the Data Provider
-
Bounded data:
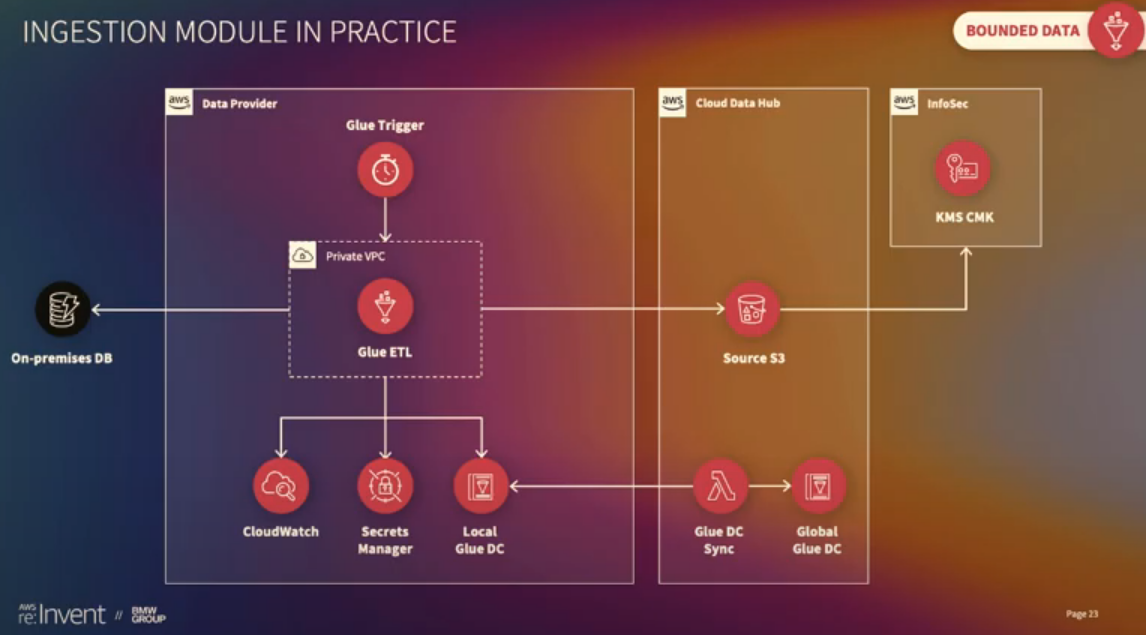
-
Glue Trigger: triggers the Glue ETL -
Glue ETL: has access to on-prem DB since it’s inside Private VPC. Uses:-
CloudWatch: log metrics -
Secrets Manager: DB secrets -
Local Glue Data Catalog: metadata
-
-
Source S3 bucket: stores all data. Resources for new data created via API -
Glue DC Sync & Global Glue DC: all metadata stored and made available to consumer accounts
-
-
Unbounded Data:

-
Kinesis: Receives data from cloud-native data providers- 1-2 minutes latency from writing data to Kinesis until it is visible in Athena
-
Firehose: Batch data to S3 -
Lambda: transforms data -
Fargate: Imports legacy Kafka topics into Kinesis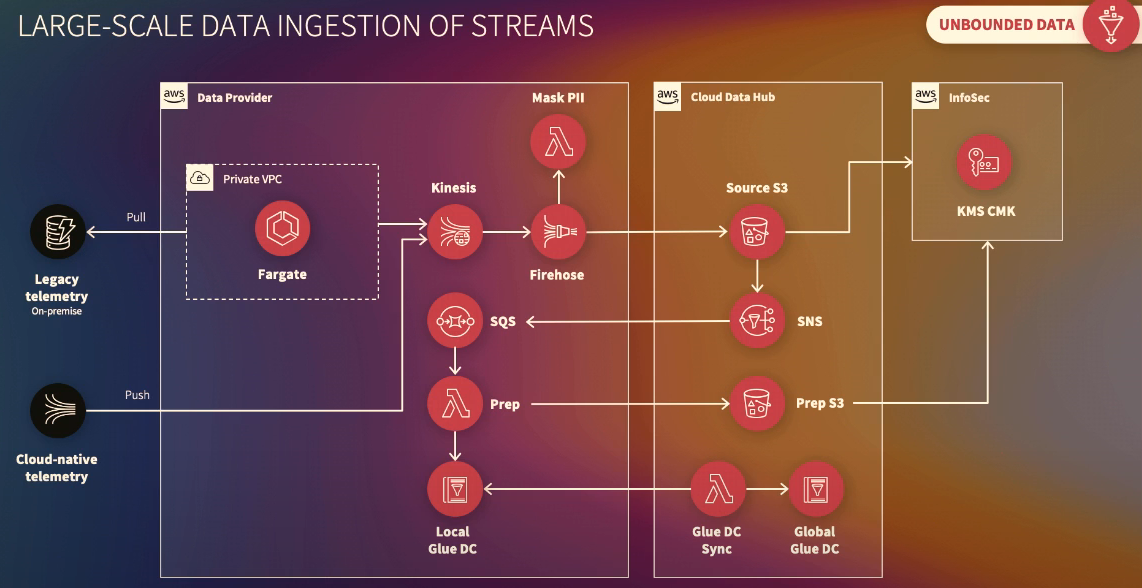
- Lambda Prep & S3 Prep Bucket: Event data enriched with data such as vehicle/customer data.
- Bucket Policies in the Source Bucket only apply to the objects owned by the bucket owner. That makes it hard for the Source Bucket to give access to consumer accounts. The solution is to use STS and roles when allowing Data Providers to feed data to the bucket.
- For services that aren’t “role-aware” like Firehose, the workaround is to trigger an event on the upload, which uses SNS and SQS to start a Lambda function that fixes ownership of the object in the bucket and before passing the data along the pipeline to be enriched.
Cloud Data Hub Highlights
- Faster and more real-time: increase latency (eg: introduce Kinesis Data Analytics)
- Metadata and lineage: improve metadata handling and data lineage tracking (from source to semantic layer), not currently reachable through API
- Search in (meta-)data: improve indexing
- Building blocks: improve customer service by building more blocks for data providers (eg: elasticsearch integration)
- Increased self-service: more features to service portal (eg: make Terraform modules available on UI)
Data Consumers
- Where data scientists and analysts use consumer accounts and advanced analytics services such as Sage Maker. It’s important that consumers have the freedom to design their own custom infrastructure along with the available building blocks and templates.
- Consumer account can also use SNS topic to trigger the processing once new data arrives.